Keras를 이용하여 이미지 데이터를 구축하고 훈련하여 테스트하는 과정을 알려드리겠습니다.
훈련시킬 이미지는 숫자이며, 이전 글인 [Opencv] 히스토그램을 이용한 숫자 인식에 사용했던 이미지입니다.

이미지 데이터가 부족하여 Python 기반 라이브러인 Augmentation을 이용하여 이미지를 왜곡시켜 증강시켰습니다.
* Augmentation에 대한 내용은 이전 글을 참고해주세요.
각 숫자별로 100장의 이미지로 부풀려 데이터셋을 구축하였습니다.
* Keras 2.2.4 / Tensorflow 1.14.0 버전을 사용했으며, 설치하신 버전을 잘 모르겠다면, 아래의 코드를 입력하여
확인하실 수 있습니다.
import tensorflow as tf
import keras
## 텐서플로우 버전
print(tf.__version__)
## 케라스 버전
print(keras.__version__)
< 훈련셋 이미지를 이용한 npy 파일 생성>
from PIL import Image
import os, glob, numpy as np
from sklearn.model_selection import train_test_split
caltech_dir = "D:/SPB_Data/.spyder-py3/test/0~10 숫자"
categories = ["0", "1", "2", "3","4", "5", "6", "7", "8", "9"]
nb_classes = len(categories) #해당하는 변수의 길이를 표현, len(categories)는 10이 된다
image_w = 28
image_h = 28
X = [] #X, Y는 데이터와 라벨을 저장하기 위해 만드는 배열
y = []
for idx, cat in enumerate(categories):
#one-hot 돌리기.
label = [0 for i in range(nb_classes)] #i = range(nb_classes) 즉 4이다.
label[idx] = 1
image_dir = caltech_dir + "/" + cat
files = glob.glob(image_dir+"/*.jpg")
print(cat, " 파일 길이 : ", len(files))
for i, f in enumerate(files):
img = Image.open(f)
img = img.convert("RGB")
img = img.resize((image_w, image_h))
data = np.asarray(img)
X.append(data)
y.append(label)
X = np.array(X)
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y)
xy = (X_train, X_test, y_train, y_test)
np.save("D:/SPB_Data/.spyder-py3/test/0~10 숫자/digit.npy", xy)
< 모델 구축 및 훈련 >
import os, glob, numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
from keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as plt
import keras.backend.tensorflow_backend as K
"Tensor 2.0에서 configproto, session 등을 변경해서 선언해야 함"
import tensorflow as tf
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.Session(config=config)
## 데이터셋 생성
X_train, X_test, y_train, y_test = np.load('D:/SPB_Data/.spyder-py3/test/0~10 숫자/digit.npy', allow_pickle=True)
print(X_train.shape)
print(X_train.shape[0])
categories = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
nb_classes = len(categories)
#일반화
X_train = X_train.astype(float) / 255
X_test = X_test.astype(float) / 255
## GPU를 이용하여 모델 구성 및 훈련
with K.tf_ops.device('/device:GPU:0'):
model = Sequential()
model.add(Conv2D(10, (3,3), input_shape=X_train.shape[1:], activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(20, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(20, activation='relu'))
model.add(Dense(nb_classes, activation='softmax'))
## 모델 학습과정 설
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_dir = 'D:/SPB_Data/.spyder-py3/test/0~10 숫자/'
if not os.path.exists(model_dir):
os.mkdir(model_dir)
model_path = model_dir + '/car_number_classification.h5'
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath=model_path , monitor='val_loss', verbose=1, save_best_only=True)
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=7)
## 모델 구성 요약
model.summary()
## 모델 학습시키기
## 배치사이즈 에포크 설정
history = model.fit(X_train, y_train, batch_size=35, epochs=60, validation_data=(X_test, y_test), callbacks=[checkpoint, early_stopping])
print("정확도 : %.4f" % (model.evaluate(X_test, y_test)[1]))

model.surmmary()를 통하여 설계된 모델을 한 눈으로 파악할 수 있으며, Convolution Layer와 Dense Layer에서
추출되는 Weight와 Bias의 수도 확인할 수 있습니다.
< 인식 >
from PIL import Image
import os, glob, numpy as np
import tensorflow as tf
caltech_dir = "D:/SPB_Data/.spyder-py3/test/0~10 숫자/9"
image_w = 28
image_h = 28
X = []
filenames = []
## 재귀함수 glob()
## 파일 내 모든 jpg 파일 로드
files = glob.glob(caltech_dir+"/*.jpg*")
for i, f in enumerate(files):
img = Image.open(f)
img = img.convert("RGB")
img = img.resize((image_w, image_h))
data = np.asarray(img, dtype='float32') # 데이터를 하나의 index(=list)를 가진 배열로 재생성 해주는 함수.
filenames.append(f)
X.append(data) # append는 이어쓰기
X = np.array(X)
# Tensor 2.0 버전의 문제인지 X는 uint8 타입으로 저장되어 지원되지 않는 형식으로 저장된다. 이때 형변환하는 함수이다.
# 밑의 함수로 변경해주거나 asarray에서 형식을 지정해줄 수도 있다.
#X = X.astype('float32')
model = tf.keras.models.load_model('D:/SPB_Data/.spyder-py3/test/0~10 숫자/number_classification.h5')
#predict는 input data가 numpy array나 list of array 형태만 가능하다.
prediction = model.predict(X)
#numpy float 출력옵션을 변경하는 함수. float 형식으로 x: 뒤에 부분을 표현한다.
#0:0.3f = 0번 index 값의 소수점 3번째 자리까지 출력함.
np.set_printoptions(formatter={'float': lambda x: "{0:0.3f}".format(x)})
cnt = 0
# 이 비교는 그냥 파일들이 있으면 해당 파일과 비교. 카테고리와 함께 비교해서 진행하는 것은 _4 파일.
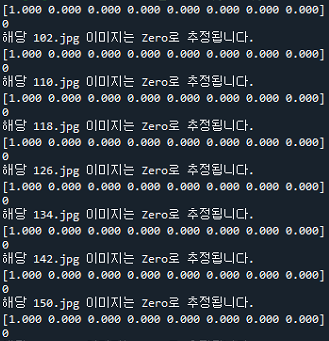
for i in prediction:
pre_ans = i.argmax() # 예측 레이블
print(i)
print(pre_ans)
pre_ans_str = ''
if pre_ans == 0: pre_ans_str = "Zero"
elif pre_ans == 1: pre_ans_str = "One"
elif pre_ans == 2: pre_ans_str = "Two"
elif pre_ans == 3: pre_ans_str = "Three"
elif pre_ans == 4: pre_ans_str = "Four"
elif pre_ans == 5: pre_ans_str = "Five"
elif pre_ans == 6: pre_ans_str = "Six"
elif pre_ans == 7: pre_ans_str = "Seven"
elif pre_ans == 8: pre_ans_str = "Eight"
else: pre_ans_str = "Nine"
if i[0] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[1] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"으로 추정됩니다.")
if i[2] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[3] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[4] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[5] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[6] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[7] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[8] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
if i[9] >= 0.8: print("해당 "+filenames[cnt].split("\\")[1]+" 이미지는 "+pre_ans_str+"로 추정됩니다.")
cnt += 1
# print(i.argmax()) #얘가 레이블 [1. 0. 0.] 이런식으로 되어 있는 것을 숫자로 바꿔주는 것.
# 즉 얘랑, 나중에 카테고리 데이터 불러와서 카테고리랑 비교를 해서 같으면 맞는거고, 아니면 틀린거로 취급하면 된다.
# 이걸 한 것은 _4.py에.
'딥러닝 > Keras' 카테고리의 다른 글
| 이미지 증강 - Augmentation (0) | 2020.04.04 |
|---|




