어떠한 프로젝트를 진행하면서 픽셀의 값을 이용한 알고리즘으로 접근할 때, 이미지 전체가 아닌 특정 영역의 픽셀 값의
정보를 알고 싶은 경우가 있었습니다. 하지만 제가 아는 것은 이미지 전체의 픽셀에 접근하여 정보를 추출하거나 캡쳐
도구를 통해 수작업으로 이미지를 잘라서 처리하는 방법 뿐이여서 불편함을 많이 느꼈습니다.
오늘은 제가 느꼈던 불편함을 해소할 수 있는 방법으로 마우스 이벤트인 setMouseCallback 함수를 이용하여,
이미지 속에서 직접 지정한 특정 영역의 이미지와 픽셀 값의 정보를 추출하는 방법에 대해 소개하려합니다.
마우스 이벤트는 사용자가 함수를 설계하여 처리할 수 있습니다.
여기서 중요한 부분은 인터럽트처럼 사용자가 설계한 함수에서의 마우스 이벤트 발생했을 때
바로 처리가 가능하도록 콜백 함수(Event Handler)를 만들어 함수를 setMouseCallback()에 등록하는 겁니다.
setMouseCallback 함수에 대해 알아보겠습니다.
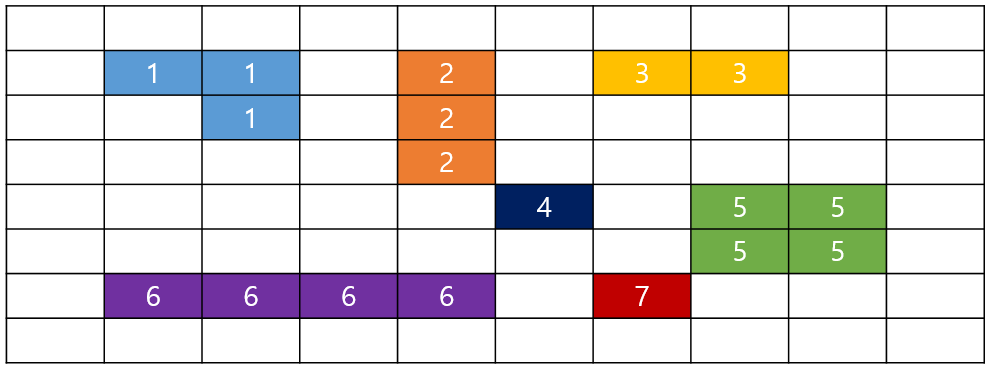
 setMouseCallback 함수 설명
setMouseCallback 함수 설명
코드를 통해 살펴보도록 하겠습니다.
아래 코드는 입력된 이미지 창에서 마우스 이벤트인 setMouseCallback 함수를 이용하여 마우스를 통해 박스를 그리고
그려진 박스 영역의 이미지를 추출해 Grayscale하여 저장한다.
(마우스는 왼쪽 버튼을 누르면 박스가 그려지는 중이 되며 뗐을 때 완전한 박스가 그려진다.
또한, Grayscale이 적용된 이미지에서 픽셀 정보를 읽어 생성된 텍스트에 입력시켜 저장한다. 추가적인 옵션으로 이미지
창에서 키보드의 SPACE를 누를 때 그려진 박스들이 사라지고 EXC를 누르면 프로그램에 종료된다.
* 본 코드는 Opencv 3.1.0 Version에서 사용하였습니다.
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
void onMouse(int x, int y, int flags, int, void *param); // 마우스 콜백 함수
void img_save(Mat img); // 이미지, 텍스트 저장
int x_1, x_2, y_1, y_2; // 그린 박스의 네 꼭짓점 좌표
int draw_start;
int draw_save;
int index = 1;
int main()
{
Mat image = imread("D:\\test.jpg");
Mat image_copy;
Mat crop_img;
Mat img_backup;
int pre_num = 0;
int r, g, b; //RGB 색상
resize(image, image, Size(500, 500), 0, 0, CV_INTER_LANCZOS4);
img_backup = image.clone();
while (1){
// 원복 복사(박스가 자연스럽게 그려지는 것을 보여주기 위함)
image_copy = image.clone();
//박스 색상(그리는 중)
r = 0;
b = 255;
g = 0;
// 박스 좌측 상단에서 우측 하단으로 그리기
if (x_1 < 0)
x_1 = 0;
if (x_2 > image_copy.cols)
x_2 = image_copy.cols;
if (y_1 < 0)
y_1 = 0;
if (y_2 > image_copy.rows)
y_2 = image_copy.rows;
// 박스 그리기
if (draw_start == 1 && draw_save == 0)
rectangle(image_copy, Point(x_1, y_1), Point(x_2, y_2), Scalar(b, g, r));
else if(draw_start == 1 && draw_save == 1){
// 박스를 자연스럽게 그리기 위함
if (x_1 > x_2) {
pre_num = x_2;
x_2 = x_1;
x_1 = pre_num;
}
if (y_1 > y_2) {
pre_num = y_2;
y_2 = y_1;
y_1 = pre_num;
}
// 이미지 저장 함수
img_save(img_backup);
// 초기화
draw_start = 0;
draw_save = 0;
index++;
// 박스 색상(그려진)
r = 255;
g = 0;
b = 0;
rectangle(image, Point(x_1, y_1), Point(x_2, y_2), Scalar(b, g, r));
// 이미지 추출
crop_img = img_backup(Range(y_1, y_2), Range(x_1, x_2));
cvtColor(crop_img, crop_img, CV_RGB2GRAY);
imshow("선택 영역", crop_img);
}
// 창에 텍스트 세기기
putText(image, "Space : Delete all box", Point(10, 15), FONT_HERSHEY_PLAIN, 1, Scalar(0, 0, 255), 2);
putText(image, " ESC : End of Program", Point(10, 35), FONT_HERSHEY_PLAIN, 1, Scalar(0, 0, 255), 2);
imshow("Original", image_copy);
setMouseCallback("Original", onMouse, 0);
if (waitKey(10) == 32)
image = img_backup.clone(); // 스페이스를 누를 시 그려진 박스 없앰
if (waitKey(5) == 27) // ESC를 누를 시 종료
exit(0);
}
//waitKey(0);
}
void img_save(Mat img)
{
FILE *pixel;
Mat save;
char buf[256]; // 이미지 저장 경로 버퍼
char buf2[256]; // 이미지 저장 경로 버퍼
int pixel_info = 0;
save = img(Range(y_1, y_2), Range(x_1, x_2));
cvtColor(save, save, CV_RGB2GRAY);
sprintf(buf, "D:\\%d.jpg", index);
imwrite(buf, save);
//픽셀 값 텍스트에 저장
sprintf(buf2, "D:\\%d.txt", index);
pixel = fopen(buf2, "w");
fprintf(pixel, "이미지 사이즈(가로,세로)\n\n", save.cols, save.rows);
fprintf(pixel, "%dx%d\n\n", save.cols, save.rows);
for (int y = 0; y < save.rows; y++){
for (int x = 0; x < save.cols; x++){
pixel_info = save.at<uchar>(y, x);
fprintf(pixel, "%03d ", pixel_info);
}
fprintf(pixel, "\n");
}
fclose(pixel);
}
void onMouse(int event, int x, int y, int flags, void * param)
{
switch (event) //switch문으로 event에 따라 버튼 종류를 구분
{
case EVENT_MOUSEMOVE: // 마우스 이동
x_2 = x;
y_2 = y;
break;
case EVENT_LBUTTONDOWN: // 마우스 왼쪽 버튼 누를 때
x_1 = x;
y_1 = y;
draw_start = 1;
break;
case EVENT_LBUTTONUP: // 마우스 왼쪽 버튼 뗄 때
draw_save = 1;
break;
}
}
 원본 이미지
원본 이미지
 영역을 지정하는 중 (파란색 박스)
영역을 지정하는 중 (파란색 박스)
 지정된 영역(빨간색)
지정된 영역(빨간색)
 추출된 지정 이미지와 픽셀 정보(GrayScale이 적용됨)
추출된 지정 이미지와 픽셀 정보(GrayScale이 적용됨)
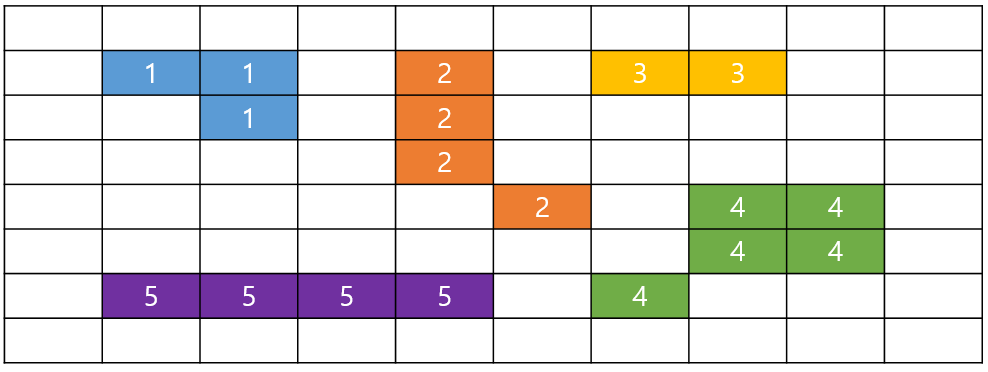
추가적으로 본 코드의 onMouse 함수를 보게 되면 여러 인자가 들어가게 된다.
인자 값은 setMouseCallback를 통해서 정보를 가져온 것들이며, 자세한 내용은 아래와 같다.

마우스 이벤트 옵션는 아래와 같으니 필요 상황에 맞춰 사용하시면 된다.

위 표의 정보는 아래의 참고 문헌을 인용하여 작성하였습니다.
< 참고 문헌 >
정성환,배종욱 지음. 2017년. OpenCV로 배우는 영상 처리 및 응용. 생능출판사